

Writing code for your website is just the fist part of being a web-developer. Debugging, maintaining, and operating a website often follows - and even if you're not the one who has to keep things up and running in the long term, understanding the end-to-end process around how you get from a URL to a fully rendered web-page will allow you to build better sites faster.
In this first article on how the web works, I'll go into some of the details around the web-browser itself, and what it is doing to render your web application.
The languages of the web
The web browser is the primary mechanism in which everyone interacts with websites or web applications. The purpose of the web-broswer is to interpet the code of the web application and render that into a page for the user.
You are most likely reading this article on one of the most popular web-browsers such as Google Chrome, Mozilla Firefox, or Microsoft Edge.
If you have already played around with some web-development, then you may be familar some of the languages involved in creating a website - there are many. In the end however, most web browsers only understand these 3 (for the most part):
- HTML (Hypertext Markup Language)
- Javascript
- CSS (Cascading Style Sheets)
There are some other languages that browsers can interpret (mostly around graphics and 3D rendering, but the 3 above are the most important ones. Each browser has a rendering engine that will interpret the HTML and CSS code to form the layout of the page and style it accordingly. The browser will also have a Javascript engine that will interpret and execute Javascript code - this code can be used to do pretty much anything - from business logic, input validation, through to editing the layout and style of the rendered page on the fly.
The most important take-away from this section, is that no matter what you actually wrote your web application in (PHP, Python, Java, C# .net, HTML, SASS), it all mostly gets compiled or transformed into those 3 languages.
On closer inspection of a page
Lets's now look at some code for a web page:
<html>
<head>
<link rel="stylesheet" href="site.css" />
</head>
<body>
<h2>Hello World!</h2>
<img src="table.jpg" width="800px"/>
</body>
</html>
This web-page is quite basic. If we were to open it in a browser, we would see a heading that says "Hello World", and an image below it. The text is styled in a specific way, and the image data itslef is clearly not in the code above - the browser has to be getting this from elsewhere.
A web browser doesn't do anything but fetch, interpret code, and render the page. So what exactly happens when we visit a site that hosts the page above?
First, we need to tell the browser that we want to fetch that page. This is the step where you, the user, enters a URL (like https://www.google.com) into the address bar. We'll get into the details of URLs, and how those get turned into actual destinations on the internet in another article in the series - all you have to know for now, is that when you hit enter after entering a URL, your browser will request send a request to that address for whatever resource is hosted there - such as an HTML page.
So if we imagine that the code above is hosted at www.example.com, then when that site gets a request from our browser, the code above gets sent back to it. At this stage, the browser interprets the HTML from top to bottom. It interprets the head section, which usually contains information about the site (we refer to this as metadata), as well as other resources. In this case, one such resource is located here: a link to a CSS file located at site.css. The broswer doesn't have this CSS file, it has to go and fetch it. So it automatically sends another web request to the address indicated by the href attribute. In this case site.css. The lack of full adddress means "the current address", so in reality, the browser requests www.example.com/site.css. At this point, the server behind www.example.com reponds with the CSS file. The browser receives this, interprets it, and makes it available for the rest of the page that is still being loaded.
Next the browser interprets the body section. The h2 tags have some text between them that the browser renders first, then it proceeds to the img tags to render an image. Here, once again, the image is a resource that is not in the html file, but rather it needs to be fetched from another source - in this case, the location is once again on the same server, and the name of the image is table.jpg. The browser requests the image from the server, and after it receives it, it is rendered on the page.

If you open the developer tools in your browser (F12 in Google Chrome) and select the "network" tab, then you can actually see the all the requests the browser makes. Refreshing the page with the network tab open will show you the following
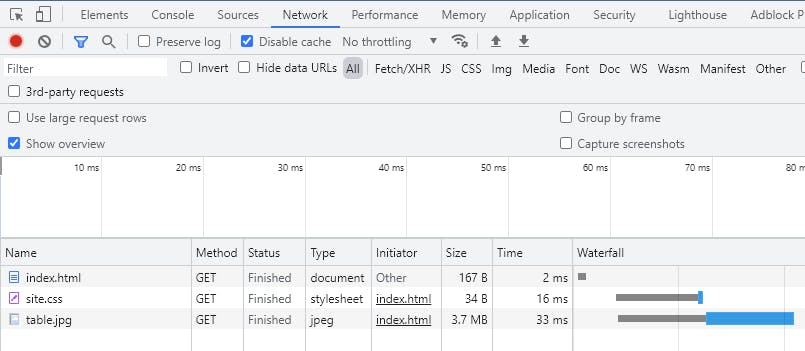
You can see that the HTML file was loaded first, and after some time the CSS file and the image file were also requested and retrieved. This is how a browser coordinates fetching all the resources for a page, when most of those resources are elsewhere in different files, and often on different servers entirely.
In later articles we will explore some of the topics such as URL -> Address translation (DNS), networking and server-side vs client-side websites. You can also follow me on Twitter here.
Happy Coding,
- Karl